The Words We Use in Data Policy: Putting People Back in the Picture
In this report we explore why and how public conversations about personal data don’t work. We suggest what must change to better include children for the sustainable future of the UK national data strategy. Our starting point is the influence of common metaphorical language.
Jeni Tennison, Vice President and Chief Strategy Adviser, Open Data Institute
There was a time when data was a nerdy and slightly obscure topic to have a conversation about. Nowadays, we talk about it all the time – data about the pandemic; data used by adtech and social media giants; data deals with trade partners; data fed to ‘mutant algorithms’.
These conversations happen between us in our homes and workplaces, but also at the national and international level. Like many other nations, the UK government has consulted on its National Data Strategy and is now proposing a “A new direction” for data protection. Internationally, in just two examples, the WHO is convening discussions on health data as a public good, and the G7 is engaging around its roadmap for “Data Free Flows with Trust”.
But data’s abstract nature makes it hard to conceptualise and talk about. And so we use metaphors. We speak of data being like oil, water or carbon dioxide; of data shadows, footprints and exhaust. Metaphors turn data into something we grasp and reason about through analogy.
Different metaphors contain within them different implications, which may or may not be accurate. In the most common and egregious example, “data is like oil” implies that it’s a precious, natural resource we should extract, own and hoard to get value from, when data’s non-rivalrous nature means it is infinitely replicable. Personally, I prefer data metaphors that highlight how we build, design, and make choices around data. At the Open Data Institute, we talk about data as infrastructure, or being like roads.
So the language we use around data is important. It influences the way we reason about it, and the data policy choices we make. This report from DefendDigitalMe focuses on the words used by Ministers, along with those used by young people, to bring these metaphors to the fore, so that we can question whether and how they match with how data works.
The choices we make now about how we collect, use and share data are ones that will have a profound effect on our future societies and economies. We need to question whether the language and metaphors we use about data help or hinder us to discuss and make decisions about that future. And as we strive towards a world where data works for everyone, we need to pay particular attention to the words and voices of the young people who will live in it.
Executive summary
In this report we explore why and how public conversations about personal data don’t work. We suggest what must change to better include children for the sustainable future of the UK national data strategy.
Our starting point is the influence of common metaphorical language: how does the way we talk about data affect our understanding of it? In turn, how does this inform policy choices, and how children feel about the use of data about them in practice?
Metaphors are routinely used by the media and politicians to describe something as something else. This brings with it associations made in response in the reader or recipient. We don’t only see the image but receive the author’s opinion or intended meaning on something.
Metaphors are very often used to influence the audience’s opinion. This is hugely important, because policy makers often use metaphors to frame and understand problems—the way you understand a problem has a big impact on how you respond to it and construct a solution.
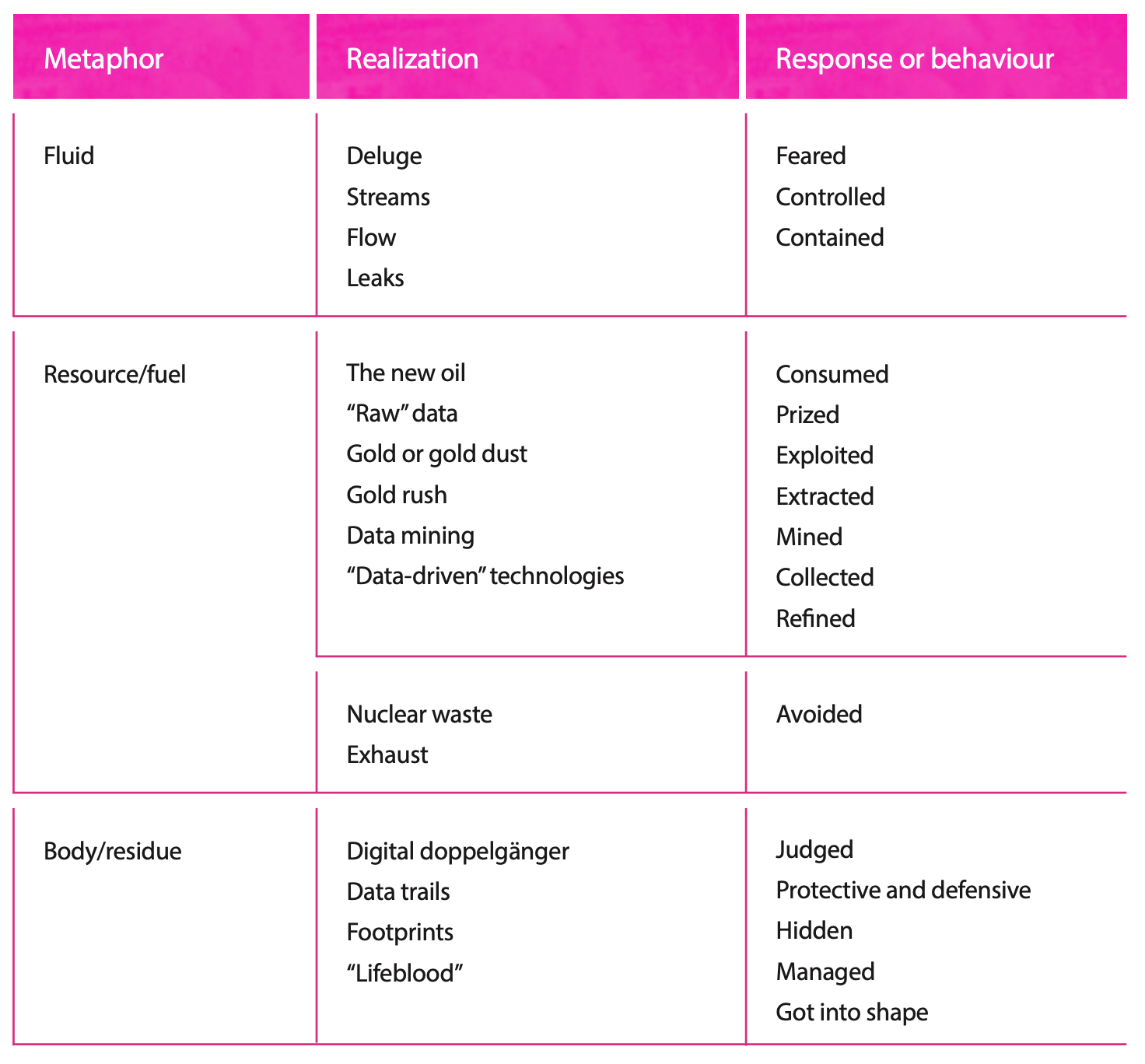
Looking at children’s policy papers and discussions about data in Parliament since 2010, we identified three metaphor groups most commonly used to describe data and its properties:
Liquid/fluid: data can both flow and leak, just like a liquid or lakes.
Resource/fuel: data can be mined; can be raw; data is ‘the new oil’ or ‘fuel for the economy’
Body / residue: data leaves a trace, like footprints. Our data is something that needs protecting.
These different framings for data each has a profound effect on people’s opinions about what should be done with it.
The liquid metaphor suggests that data is something that’s unpredictable and difficult to control, while the resource metaphor invokes the idea that data is something we can exploit and extract value from. Finally, the body/residue metaphors treat data as something which makes us vulnerable, or left behind in a predatory environment, and so its use is something we should both fear and protect.
In our workshop at The Warren Youth Project, the participants used all of our identified metaphors in different ways. Some talked about the extraction of data being destructive, while others likened it to a concept that follows you around from the moment you’re born. There were three key themes that emerged from our discussions:
Misrepresentation: the participants felt that data was often inaccurate, or used by third parties as a single source of truth in decision-making. In these cases, there was a sense that they had no control over how they were perceived by law enforcement, and other authority figures.
Power hierarchies and abuses of power: this theme came out via numerous stories about those with authority over the participants having seemingly unfettered access to their data, thus enforcing opaque processes, leaving the participants powerless and with no control.
The use of data ‘in your best interest’: there was unease expressed over data being used or collected for reasons that were unclear and defined by adults, leaving children with lack of agency and autonomy.
When looking into how children are framed in data policy we found that they are most commonly represented as criminals or victims, or simply missing in the discussion. The National Data Strategy makes a lot of claims of how data can be of use to society in the UK, but only mentions children twice and mostly talks about data like it’s a resource to be exploited for economic gain.
The language in this strategy and in other policy documents is alienating, and dehumanises children into data points for the purposes of predicting criminal behaviour, or attempt to protect them from online harms. The voices of children themselves are left out of the conversation entirely.
We propose new and better ways to talk about personal data. We want policy makers to
recognise the human in the data and involve people across the data life cycle
talk about data as something more personal than just an economic or political tool, remembering to protect human dignity and human flourishing
promote the required infrastructure for data management that sustainable data governance requires.
National data policy is no different from other national policy. It should recognise the holistic needs of children, with the awareness embodied in the UN Convention on the Rights of the Child, that while children are still developing and they need protection, they also need State policy to respect their rights to privacy and to participation.
Policy makers must give young people and their legal guardians ways to exercise their rights to an active role in the use of data about them, across the wide range of their civil, political, economic, social and cultural environments; and promote their full flourishing into adulthood.
We are at a critical time in forming the National Data Strategy and how the infrastructure and policy will shape and be shaped by the use of both third party and national administrative datasets for the next twenty years. Just as today’s children develop into adulthood. Yet it fails to take children’s views into account.
We seek to redress that balance.
The way you understand a problem has a big impact on how you construct a solution.”
Conceptual Metaphor Theory
How metaphors help us frame problems, and ultimately form solutions
To get an understanding of how and why common data metaphors shape our thinking and young people’s experiences of what role data plays in their lives, we need to better understand the power of metaphorical language.
The conceptual metaphor, and its role in language and the mind, is an idea presented by George Lakoff and Mark Johnson in Metaphors We Live By. They wrote that up until the 1970s, metaphors were mostly seen as a descriptive tool to illustrate a point or how the speaker thinks or feels about something. Such as: “getting people to sign my petition is like pulling teeth”. A metaphor like this is used to better describe the speaker’s opinion, and while not intended to influence the opinions of others, still carries with it connotations.
Later academics also analysed how metaphors also play a role in shaping decision-making: we use them all the time to explain or understand complex and abstract concepts. This can be helpful in communicating problems (so that you can find solutions), but metaphorical language used to create analogies and scenarios draws on what you already know, and thus plays a part in cognitive processes, influencing people’s opinions — and in turn, informing their decisions.
This process is demonstrated in Metaphors We Think With: The Role of Metaphor in Reasoning, a 2011 study (Boroditsky and Thibodeau) on how linguistic metaphors affect our reasoning.
The study looked at the problem of crime, and asked participants about their ideas for possible solutions. Participants read two versions of the same paragraph, describing crime rates in a fictional town called Addison: one version characterised crime as a wild beast that was preying on the town. The other likened crime to a virus that had infected the town.
Even fleeting and seemingly unnoticed metaphors in natural language can represent complex knowledge structures and influence people’s reasoning.
These two framings each had a profound effect on how the participants decided they might tackle the problem of crime in Addison:
1. When presented with the wild beast metaphor, participants were much more likely to suggest solutions around law enforcement. Things like: building more prisons, bringing in the national guard, or introducing harsher penalties.
2. Those responding to the virus metaphor were more likely to suggest solutions that were centred around reform, such as: looking for the root cause, improving education, or providing more healthcare.
While the metaphors were not the sole driver of decision-making in this scenario (the participants were also given crime stats and other facts), they played an important part in helping participants conceptualise the problem, and therefore how they approach the solution.
This brings us neatly to the concept of generative metaphors, which was introduced by Donald Schon in a 1979 paper. Schon explains that the issue in societal problem-solving is not finding the solution, but more about the framing of the problem itself. How we understand the problem has a large effect on how we approach the solution — and if metaphors are used in problem setting, then they are hugely important in how we make decisions.
Data is the business model of the Internet age.”
How data has been described by ministers in Parliament
Policy makers have demonstrated time and time again that they still struggle to describe data well.
During a House of Commons debate about data protection in December 2020, the Minister for Digital and the Shadow Minister for Digital were unable to really agree on good metaphors for describing data, and touched on all three of our identified types.
Both quotes are taken from Draft Data Protection Privacy and electronic communications (amendment etc.) (EU exit) regulations 2020, November 25, 2020.
Common Data Metaphors We Use Today
Data is most often three things in current debate: a fluid, a resource, or bodily related
The significance of common metaphors used to frame a problem and how we approach the solution should not be underestimated.
We now collectively produce more data as a result of our behaviour than ever before. Most people are not privy to the processes behind digital products and services that result in data collection and analysis — but there is broadly consensus that data is valuable. Therefore the concept of ‘personal data’ has been under a lot of scrutiny in the last decade; and what can be complex conversations are full of metaphors in an attempt to better understand what’s going on. A lot of academic and journalistic debates frame data as ‘the new oil’, for example; while some others describe it as toxic residue or nuclear waste. The range of metaphors used by politicians is more narrow and rarely as critical.
Through our research we’ve identified the
three most prominent sets of metaphors
for data used in reports and policy documents. These are:
Fluid: data can flow or leak
A resource/fuel: data can be mined, can be raw, data is like oil
Body or bodily residue: data can be left behind by a person like footprints; data needs protecting
These metaphors are fairly distinct from each other, and therefore have potential to encourage very different responses. Let’s look at these three data metaphors in more detail.
Fluid
The fluid metaphor is extremely common in how people describe data: a ‘data leak’ or ‘data breach’ are widely understood terms. Margie Cheesman wrote in 2017 about how contemporary discourse about data mapping in the context of migration seems to favour the fluid metaphor and this reinforces the sentiment that big data is difficult to control: “the data deluge comes in streams, flows, and pools, leaking here and there”. This framing in turn makes for “an unhelpful, de-humanizing lexicon in discourse about migration” [itself].
Framing data as a fluid which flows, leaks, and rises in unexpected ways might suggest that it’s something we should fear and that we cannot control, just like a natural disaster. Data leaks ‘just happen’ and are difficult to predict; data flows from one place to another. This metaphor embodies the characteristics of the movement of data and simplifies the concept of data transfer.
Resource or fuel
The resource or fuel metaphor is most commonly used in public debate, arguing that data can even be seen as a new ‘asset class’. An influential example being The World Economic Forum’s 2011 report, which describes data as ‘the new oil’ and a ‘valuable resource for the 21st century’.
In a similar vein, when you describe a process as being ‘data-driven’, this suggests it’s powered by data in the same way petrol powers a car. In Metaphors of Big Data Puschmann and Burgess suggest that there is a cognitive link between how cars consume petrol, and how humans consume food. Expanding this to data frames it neatly as something that exists within industry, and as a necessary part of consumer culture.
By assuming that data is much like a natural resource, we start to see data as something which appears miraculously, free for us to harvest, and not something that is governed and manipulated by humans. In The Atlantic in 2015, Tim Hwang and Karen Levy point out, often “people are nowhere to be found” in this landscape of data metaphors, which “do us a disservice by masking the human behaviours, relationships, and communications that make up all that data we’re streaming and mining.”
This metaphor embodies the characteristics of the data as a commodity.
Maciej Cegłowski and Cory Doctorow separately speak of data as toxic nuclear waste, a by-product of this “data as fuel” analogy. While not as commonly used as the fuel metaphor, policy makers should note the element of harm that is introduced by these framings. Which metaphors have persisted in the media and where they are most used is undoubtedly worth further research, but is out of scope for this paper.
Bodily related or as a residue
The body metaphor is more personal and emotionally charged: describing data as something that is left behind like a trail or a footprint invokes the idea that data can leave a mark to follow in physical space.
Some will also look at this physical embodiment of data as more of a shadow or second self. In a 2018 blog post Deborah Lupton looked at an Experian ad campaign called ‘Meet Your Digital Self’ which characterised personal data as something that takes shape as a digital double of you, your doppelgänger. One poster reads, “Your Data Self is the version of you that companies see when you apply for things like credit cards, loans and mortgages. You two should get acquainted”. This suggests that your doppelgänger is constantly being judged or analysed by other parties — and that you need to get it into shape.
In this framing, ‘data as body’ centres the individual as someone who is responsible for hiding or protecting their data — otherwise they leave themselves vulnerable to being tracked and targeted. This metaphor suggests data exposure is the responsibility of the person the data comes from, often in a predatory or judgemental environment about your behaviour.
Children are being ‘datafied’ with companies and organisations recording many thousands of data points about them as they grow up.”
How data is described in children’s policy documents
The policy documents we have read in our research often show how data use relating to children is problematic. These use cases, and the language used to describe them in these documents, tend towards seeing data about children as often very separate from the children it is about and they are excluded from its processing. Recognising this is the exception.
Just as debate often steers towards misrepresentation of personal data as something ‘depersonalised’, it also dehumanises the involvement of people in the process. The social, cultural and political realities in which policy makers work, influence the metaphors they reach for, consciously or not.
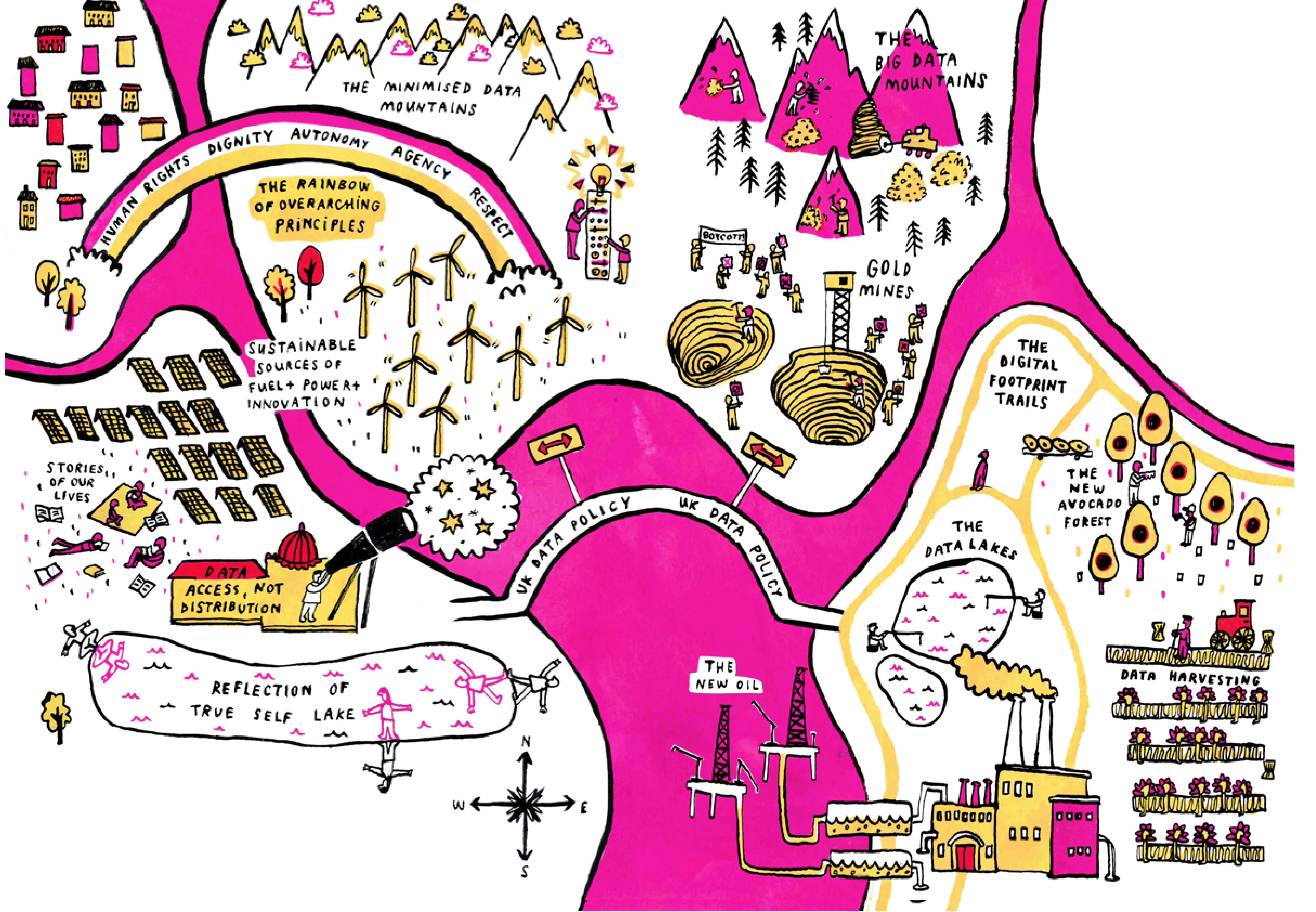
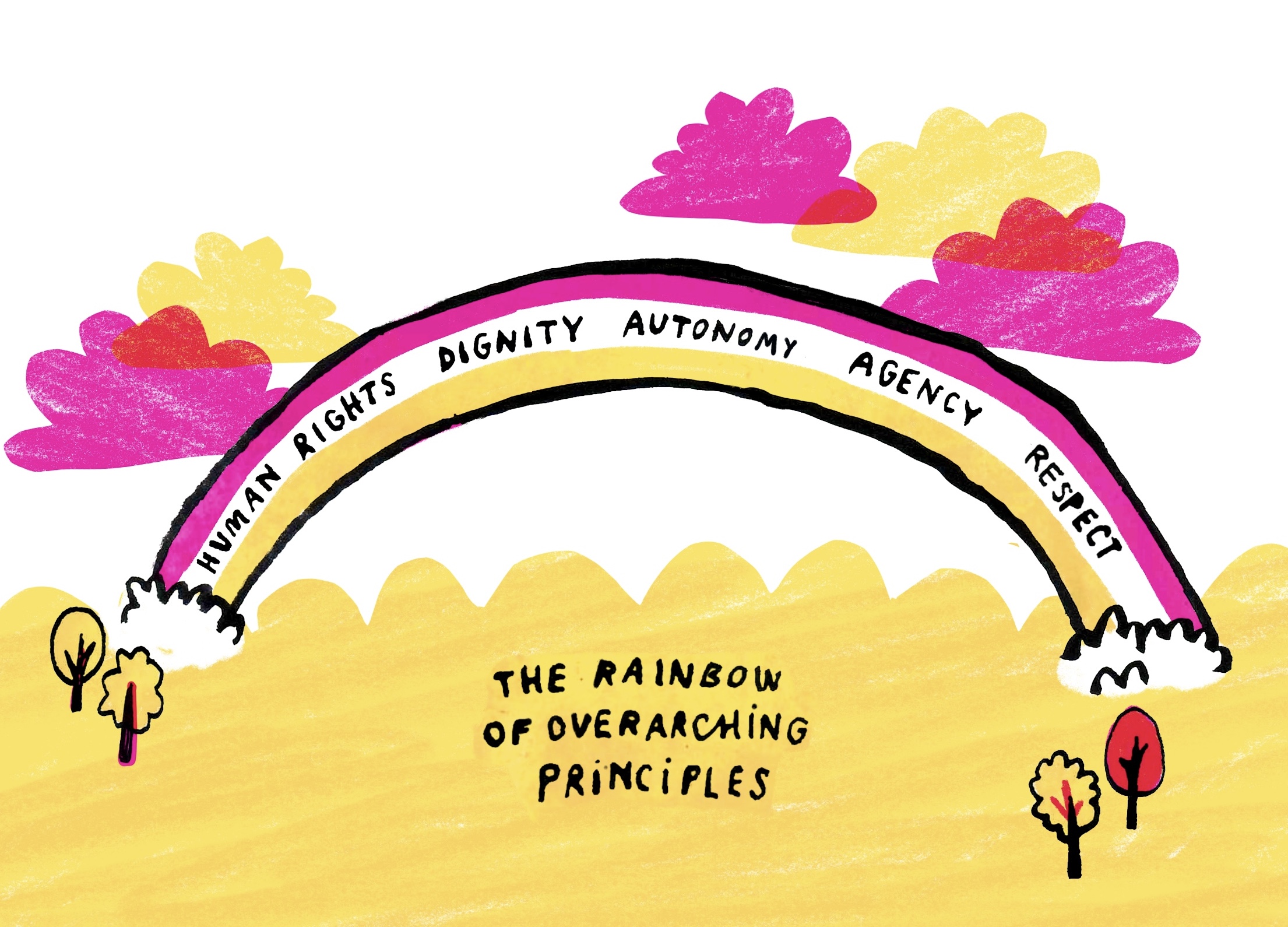
Young people envisage a landscape which supports data access not distribution, in which they have controls over its use with respect for their life stories. There is recognition of the fallibility of the partial knowledge that data reflects about them. This is a sustainable ecosystem governed by overarching principles that promote human flourishing.
In the current digital landscape personal data is a product to mine, extract and exploit and pass around to others. Data collection is excessive in "Big Data" mountains and data lakes, described like the EU food surpluses of the 1970s. Extraction and use without effective controls creates toxic waste, is polluting and met with resistance.
This environment is not sustainable.
Young people’s voices and experiences with ‘data’
Findings from our workshop at The Warren Youth Project, where a group of young people shared what their everyday experiences of data used about them, means to them, and why.
Policy makers have demonstrated time and time again that they still struggle to describe data well.
During a House of Commons debate about data protection in December 2020, the Minister for Digital and the Shadow Minister for Digital were unable to really agree on good metaphors for describing data, and touched on all three of our identified types.
Both quotes are taken from Draft Data Protection Privacy and electronic communications (amendment etc.) (EU exit) regulations 2020, November 25, 2020.
As part of our thinking, we ran a workshop with participants between the ages of 14 and 21. The workshop was facilitated by Alice Thwaite.
The participants discussed what data means to them and three key themes developed:
Misrepresentation
Power hierarchies and abuses of power
Agency and control over what data used ‘in your best interests’ may mean
Misrepresentation
This theme emerged early in the discussion; after talking about the functional uses of data, one participant pointed out that data is never as accurate as we assume it is, because it is incomplete or “you can lie about it.”
This was a particularly pertinent point, because the group identified data as something that others collect, in order to ‘know more about you’. Those others will rely on data to make decisions, even if the data is inaccurate and not representative of you at all.
Matt shared an experience they had with the police when they were around 16 or 17: the police had collected data about Matt without his knowledge, and then accused Matt of lying because what he said to the police officer at the time did not match the interpretation of data extracted from his mobile phone— demonstrating that more trust is often put into data than humans.
Alex noted that their birth certificate reads ‘male’ under gender even though they are non-binary: “it doesn’t reflect who I am and my brain chemistry... it was just written on paper almost 20 years ago”.
As the academic Jeffrey Reimann recognised in 1976, the young people reflected that privacy matters to them as a representation of their self as part of their development and in a relationship to others.
”Privacy is necessary to the creation of selves out of human beings, since a self is at least in part a human being who regards his existence, his thoughts, his body, his actions as his own.”
“policemen will just rely on data, like name, date, binary information, but I have my own truths, nothing and no one can tell me what I am” — Alex
Mental health and well-being were important themes throughout the discussion. Participants quickly picked up on the mental health implications of “humans as machines” metaphors: Josh talked about “people ‘breaking down’, or not having the will to move, has to do with mental health”. Alex suggested “needing to recharge your battery when you’re tired” as a similar metaphor and observed, “when we say people have broken down, it makes it seem like something that can just be fixed easily, or to push aside the actual problem.” They noticed this language can “help censor and soften people to process things, can suppress a little bit how something might be affecting someone.” Chris also noted a strange contradiction: “we say a phone dies, but a person ‘passed away.’”
Chris suggested, “We use tech language on humans to [...] distance ourselves from the person we’re talking about.”
The participants agreed that being misrepresented by data has damaging consequences, which is why it is incredibly important to have control over your data to have control over how you are represented and ultimately, control over your life
Power hierarchies and abuses of power
Alex closely related data to authority figures, and used a body metaphor: “data is a concept that follows you around from even before you are born and for some reason, in some situations it can dictate how people deal with and treat you.” “You have a data double.”
In this sense, data can make you vulnerable. Authority figures often seem to have access to data without your awareness that the data even exists — therefore the system appears opaque and the power in a relationship between people and institutions is out of balance.
One participant shared their story of being put under a wrongful arrest for possession of a firearm. They were told that there was some data on file that led to this decision, but when they asked to see the data they were refused. The group suggested this person could exercise their rights under data protection law to find out what their records said.
This led to a discussion about how large and powerful organisations do not have the same rules applied to them; large tech firms will collect and process data with no regard for what effect it has on the world. In this discussion, Chris likened data to oil, saying that extracting oil “can be destructive for the surrounding environment [just as] some of the ways our data is mined, used, and processed is quite destructive.”
There was also an observation that authorities don’t seem to care about truth, and would rather use data as a conduit for communicating, instead of a one-on- one chat between people. Josh mentioned that a lot of his friends are deaf, and if they get pulled over by the police, they will sometimes “get arrested because they can’t understand them. They make them write on paper which is more confusing. Why can’t they learn it [sign language] instead of collecting more data?”
Uses of data “in your best interests” and agency
This part of the discussion focussed on trust and transparency; participants felt differently about their data being collected, depending on whether it was an organisation they knew or trusted. When asked how they felt about The Warren collecting their data when they enter the building, Josh explained that he trusted who would use it and why. The “data don’t go to no one else, I would say it’s needed for safety, like who’s in the building, for safeguarding reasons”.
Some participants mentioned that we are heavily reliant on data and technology and the authority given to it, with one saying that “computers are the lifeblood of modern society”. There were questions raised as to whether we even needed data in some situations, and Chris said that they felt uncomfortable being seen “as a number”.
“when you’re born, data, technology, people know things about you, know more than you do about yourself. Some people think that just because data is laid out in a format, that means it must be correct” — Josh
“I feel as if we use human metaphor language, on technology so we can feel more attached to it as well as representing how reliant we are on tech” — Joe
In contrast, Josh described a counselling situation where a number was used in place of a name, as a good way to preserve privacy to some degree.
The participants described how they feel when their datafied self replaces talking to them directly. Data used as a kind of ‘middle-person’ between the child and the adult can be both good and bad. Chris mentioned that using data in this way can be useful because you can “write down exactly what happened”. This is key, especially in the context of interactions with authority figures, as described earlier. But the risk of looking at data as a ‘middle-person’ is that “it’s used a lot more than it should actually be, used in ways other than it’s intended”.
The young people said that use of data about them instead of what they said themselves, removed their agency.
The young people clearly understand that the uses of data can be both beneficial or harmful, for and against an individual’s best interest. They expressed unease that data about them used to replace conversation with them can mean they are misrepresented, and at the same time there is a paradox that a piece of data can be the single source of truth advocating on your behalf.
This discussion echoed Lupton and Williamson’s conclusions in The datafied child (Lupton and Williamson, 2017), that in many approaches to the datafication and dataveillance of children, “the embodied and subjective voices of children are displaced by the supposed impartial objectivity provided by the technological mouthpieces of data...data are positioned in ways that override the rights of children to speak for themselves.”
How children are framed in UK national data policy
The language policy makers use when describing data dehumanises children — what effect will this have on the future of our data strategy?
The way children are framed in national data policies is critically important; this framing will ultimately shape which issues are prioritised, and crucially, which are funded. Our current framing appears to have spawned policies which assume that children are either criminals or victims, part of “Troubled Families” or ignored.
The National Data Strategy is a policy document produced by the Department for Digital, Culture, Media & Sport (DCMS), which details how the UK government will deal with data going forward. This Strategy is therefore meant to define: ”a framework for the action this government will take on data [...] unlocking the power of data for the UK, and the missions that we must prioritise now”.
The Strategy is described as just the beginning of the conversation despite the fact that data governance is a problem we’ve been struggling with in policy debates for over a decade.
Children are hardly included in the strategy at all.
In fact, it only mentions children twice: once in section 6.1.4, where children aren’t even in focus, but rather they are creators of behavioural data through the “monitoring and reporting of online harms” and the focus is “deriving value” from that. The second mention in is section 6.2.1, which discusses how data can help prevent child abuse. Children are framed in the strategy as a vulnerable subset of society in need of protection but even that should be monetised by companies.
While there is a commitment to deliver the strategy through collaboration and in a way that builds public trust, there is nothing that describes how that will be achieved or sustained.
Government research interests: are children doomed?
The recommendations in the cross government
review on use of data, Joined up data in government: the future of data linking methods (2020) are a good example of this dehumanisation: these documents outline new infrastructures to safely link different data sets together, and in the only case study that mentions children, in which children are called either ‘pupils’ or ‘offenders’: the case study drew together research by linking up prison records with education data, and other details from their lives, in order to identify patterns of criminal behaviour
This case study does not discuss much of the practical uses for this research, besides attempting to predict when crime might occur within a very small subset of children.
In a 2017 debate on Data Protection and Leaving the EU, Vicky Ford (current Minister for Children and Families) likened data to something necessary for the survival of the system, by saying that “data is the lifeblood of the modern economy” but at what cost to children?
In state education the volume of children’s data collection and commercial distribution is vast, as we mapped out in our defenddigitalme #StateOfData2020 report. We found that children have lost control of their digital footprint by their fifth birthday. Technology (edTech) used in educational settings and the debate this year may be framed by data governance enforcement by the Information Commissioner’s Office of the Age Appropriate Design Code. It takes its framing from recital 38 in the GDPR recognising that children are vulnerable and require additional protections. This goes beyond data protection law in taking its lead principle from the UNCRC Article 3 the Best Interests of the Child. How it will be operationalised remains to be seen.
It is widely understood among students that schools passively gather data about them, such as attendance records, and exam grades. Children may not expect, however, that under our current state system, this data is also up for grabs for commercial reuse and research purposes. National pupil data is routinely copied and distributed to thousands of third parties. The current process removes any active role a child has in controlling data about themselves, and dehumanises the complexity of children’s lives into hundreds of data points.
Other recent digital policy debates, such as The Online Harms agenda look at children as victims in need of protection from unseen online forces such as cyberbullying, loneliness, and radicalisation. Once again, the focus of research is not on building a future-facing vision for children’s holistic needs, but rather on surveilling what they do online and DCMS promotion of a SafetyTech market to do so.
Policy conflicts from the same government Department that claims to want to make the UK the safest place to go online for children.
In the context of Online Harms, children need better quality debate that recognises children not only as a faceless collective but as individuals and as rights holders. That recognition in law again demands attention is paid to the obligations of duty bearers. Alongside our research on the application of ‘the best interests of the child’ in the digital environment, how language is used and weaponised in culture wars, shaping policy not only for children, but for everyone of all ages online.
Terri Dowty’s conclusion from her 2008 article, Overlooking children: An experiment with consequences, could be contemporary when she wrote, ”it is surprising so many children survive our doomsday prognoses for them.”
What would a long term positive policy vision for children look like instead and what would it need in terms of support through data management?
When it comes to a long term data vision for sustainable data use, children are left out entirely.
It’s hard to imagine a sustainable future for our digital landscape if the language that policy-makers use to describe data is all about mining and extracting value, rather than consulting children on how they see data playing a part in their future and their part in it.
Ensuring we have not only metaphorical but physically sustainable models in place for storing data and safe access across its life cycle is a key part of realising that future that matters to young people.
The quality and robustness of infrastructure in public administrative data storage and management, requires investment. The reality of our current infrastructure is that it is poor. It takes both money and human capital to sustain systems. Despite the UK government claims in its national data strategy there is no new investment promised, and it has consistently underinvested to date.
In late 2020, the government shut down its Registers programme without introducing an equivalent alternative, and the Personal Data Exchange programme never moved beyond a pilot phase. The data distribution registers made under the public service delivery, debt, fraud and civil registration provisions within the Digital Economy Act 2017 are necessary and should be expanded to other sectors but are currently limited in scope and too slow in their development.
While refusing to invest in data infrastructure programmes (over which government rather than private sector organisations have oversight) government routinely expands the data it collects and holds centrally via new programmes like GOV. UK accounts or from children specifically, through annual school census expansions year-on-year. those expansions increasingly meet resistance and the warning signs are that this is unsustainable.
For systems to be sustainable we must also consider their physical place in the world and what that future looks like, whether it has buy-in, and its impact on today’s children as future decision-makers and participants in society.
Rachel Coldicutt, then CEO of DotEveryone, and now founder of Careful Industries, summarised in a 2019 speech: “The carbon cost of collecting and storing data no one can use is already a moral issue. So before you add another field, let alone make a new service, can you be sure it will make enough of a difference to legitimise its impact on the planet?”
The carbon cost of collecting and storing data no one can use is already a moral issue.”
The consistent and wilful refusal to construct any kind of sustainable data infrastructure that involves children implicitly excludes children from having any power over the future of their data. The children we spoke to in our workshop at The Warren made it clear that the current public conversation does not fit with their feelings or expectations on data.
Building trust means building a relationship. What relationship can we have to data about us, if we are excluded from the processes about it? Involvement means having a clear process and rights’ management infrastructure in which people are active and supportive.
How can a school or GP or Job Centre show me that when you collect stories about my life that will be shared with others, that will be done in ways that are trustworthy and will not be used to harm my interests? What receipt do I get to show what was done? What process is in place for me to report changes and corrections over time?
Access to and the availability of data beyond the short-term vision of the National Data Strategy, depends upon the trust of today’s children.
Active choices needs physical infrastructure
The recent Centre for Data Ethics and Innovation, Doteveryone, and Behavioural Insights Unit joint report, Active Online Choices: Designing to Empower Users sums this up as, active choices.
When it comes to personal data, understanding those consequences means an ongoing continuous relationship is needed to maintain trust, not only a transactional single sign-off at the point of collection. People need to know that their data rights exist and how to exercise them for the full data life cycle.
The right to be informed
The right of access
The right to rectification
The right to erasure
The right to restrict processing
The right to data portability
The right to object
Rights in relation to automated decision making and profiling
The need to include children and families in the national conversation about data has never been so urgent.”
There are no consistent mechanisms in place for example in the state education sector that enable the exercise of these rights by legal guardians under the UNCRC Articles 5 and 18, or explanations available for schools how they should be considered in balancing such rights, in a manner consistent with the evolving capacities of the child. We address this further in our forthcoming working paper on the Best Interests of the Child in the context of the ICO Age Appropriate Design Code. There needs to be physical infrastructure to enable the communications around data between all parties involved: families, schools and both local and national government.
The need to include children and families in the national conversation about data has never been so urgent: just in the last four years, we’ve seen a steady increase in legislation which seeks to collect huge amounts of data, and reduce children into data subjects of all ages in the Higher Education and Research Act 2017 from students and starting younger and younger — most recently the Reception Baseline Assessment scheduled to start in September 2021 that will extract data from four year olds just starting school, creating their first records in the permanent National Pupil Database.
Systems are meant to work for people
The child’s right to protection against economic exploitation is enshrined in Article 32 of the United Nations Convention on the Rights of the Child (UNCRC) and while it is generally interpreted as the child’s right to protection against child labour (van der Hof et al.) UK policy makers should consider this as it apples to labour in the digital environment.
There are clear parallels in both teachers’ and children’s work being performed in state school systems and digital tools being used to produce data, which is then mined as a commodity by commercial companies for their own product development and profit. (Selwyn).
While children are seen as in need of protection from online harms and in the online safety tech agenda, there is little attention paid to preventing the potential for more exploitation resulting in the trade off from using technology such as age assurance and age verification, or addition data collection from children and their relations to verify a child’s identity.
The National Data Strategy makes big, sweeping propositions, but the UK currently lacks any kind of people-centric data governance infrastructure proposals needed to carry the propositions forward.
The National Data Strategy must operationalise the infrastructure to enable the involvement of people in processes about them, to exercise their rights that data governance law enshrines. A sustainable future is one compatible with data used for economic growth and also one in which people can see and control data about themselves, can correct it, or give others access for use in trusted ways that we feel comfortable with and the effects it has on our lives.
As the CDEI said in 2020: a failure to engage effectively with the public is therefore not only an ethical risk, but a risk to the speed of innovation.”
Both the DCMS 10 Tech Priorities and latest press release (September 2021) suggest “removing barriers to responsible data sharing and use” but neither defines what those are supposed to be.
The 2021 AI-Council Roadmap suggestion that, “The UK should lead in developing appropriate standards to frame the future governance of data” should be more clear in explaining what appropriate trans-national governance standards already exist in law and how any new proposal would be different.
The Roadmap makes recommendations on the place of people as “a steady supply of skilled entrants to the workforce” but omits how students might be educated on how AI is dependent on data from people as its “lifeblood”.
Institutions must engage with the moral as well as practical questions of whether young people should be steered into “emerging AI professions” to form a new pool of human capital based on transient political aspiration and at what costs. There is obvious potential to exacerbate the digital divide not only as we know it today, but in AI reaffirming the power imbalance between the users and the used. There seems little clear effort is being made on increasing synergy or skills between subsectors or to distribute resources strategically rather than in a scatter gun ‘point-and-shoot’ approach.
Children already understand how data supports and benefits their everyday life. But at the same time they are fed up feeling exploited. This is not solved by treating the subject as a communications challenge. We must include children in the national conversation and policy makers’ thinking about data in ways that frame children as more than just criminals or victims, as human capital or ignores them. It is difficult to picture a positive future in policy that respects the full range of children’s human rights, when we don’t talk about children as rounded human beings.
Policy must consider ways in which children can exercise their data rights and trust that data users will uphold them. Children cannot be empowered to make decisions about their future if what matters to them in their lives is abstracted into data points and statistics over which they have no control.
Children expect data about them to be treated with fairness and the respect and humanity that they expect in the treatment of themselves and for one another.
Understanding UK data governance
The crux of the failure of how we talk about personal data is a failure of thinking and struggle to reconcile the differences between US and UK approaches to data governance and law
Policy makers in the US use more traditional consumer and transactional terms that describe data as a commodity that can be owned, and which sends the message that those in power can exploit and trade it for economic gain. The people the data is about are not involved in that process beyond the point of collection and are not in control of future decisions.
In Europe, data governance is founded on a human rights framework, and our data laws focus on control and informed decision making over the use of personal data by people. Here, the people whom the data are about must remain involved in its processing across the data life cycle, to be able to understand what data is being processed, by whom, why, for how long and be able to do things like ensure data accuracy.
This fundamental difference between US and European thinking is revealed in the language that some UK policy makers use to talk about data, using US-centric terms. Politicians here trip over metaphors that don’t work in conversations about data because the language they use is out of step with UK laws that they are trying to discuss and shape. Fixing this is an opportunity to improve common understanding across different policy makers. It matters to be able to understand why there is a misalignment between thinking expressed in the words used in debate, and thinking about the law. Both need joined up to frame better decisions what needs to be done to deliver the aims of the UK national data strategy and which can be entirely compatible with a rights’ based data governance model.
Some still struggle thinking about what personal data is and therefore when data protection law applies. The UK National Data Strategy is blinkered by its focus on “sharing” and “opening up data for commercial benefit and social good” or encouraging “the availability of private sector data” without any clear separation of thinking between personal data and non-personal data. This is the second opportunity for the National Data Strategy. Making this distinction clearer and acknowledging the need to operationalise governance of personal data would help assign roles and responsibilities.
For example in managing the change required to create capability in organisations to offer people active choices, and the infrastructure the country needs for individuals’ involvement around their publicly held personal data in administrative datasets.
Since data protection law applies even to personal data that is de-identified or pseudonymised, and anonymisation is notoriously hard, there is little value in spending great efforts to try to define any fine differences. Data that comes from people’s behaviour is almost always personal data at some point, regardless of whether a person volunteered it, or whether it was inferred or observed.
A third opportunity for improving the National Data Strategy is to consider the changing nature of personal data over time. Data may sit on a spectrum from open to closed, personal to non-personal, completeness and accuracy, ethical to unethical uses, but those characteristics are moveable and may be contextual and may switch or degrade for the same data at different times and over its entire life cycle.
This concept of data having a shelf-life is where one metaphor we came across in the media, stood out among others, ‘data is the new avocado’. But as Elms summarises well in that article, “Rather than stretch for analogies that do not fit well and lead officials to regulate data poorly, it is perhaps time to stop discussing analogies at all.”
Any National Data Strategy will be actionable only once it embraces an understanding that personal data has different properties, different permissions, and different limitations at different times in the data life cycle, and those change over time in inconsistent ways.
This comes from the intrinsic nature of personal data itself and its inseparable relationship to people, who must be informed and involved in its processing if the process is to remain trustworthy over time. This demands a data management infrastructure with clear roles and responsibilities of people embedded in the process.
Further to a better understanding that the characteristics of personal data are in flux and connected to the person the data is about or even many people at the same time, a working knowledge of the development of the UK data governance regime over time and its underpinning values, is critical to understand why today’s metaphors don’t work.
Understanding the origins of writing that governance, is key to understanding why today’s data governance model is about people first, not products.
A simplified history of UK and US data governance models
The House of Lords 2018 Data Protection Bill Explanatory Notes set out this story well, some of which we abridge. We are grateful to Douwe Korff and Ian Brown for enhancing our knowledge of this history.
A postcard-sized summary from the US
In 1948 The Universal Declaration of Human Rights was adopted, including by the US, with its 12th fundamental right, the Right to Privacy, in response to the “barbarous acts which [...] outraged the conscience of mankind” during the Second World War.
The US Health Education and Welfare report in 1973 proposed many of the fair processing principles which became part of the Privacy Act of 1974 applying to the federal government, and work began in 1978 at the Organisation for Economic Co-operation and Development (OECD) to develop guidelines on basic rules governing the transborder flow and the protection of personal data and privacy, in order to facilitate a harmonisation of national legislations.
In 2009, the U.S. Privacy Coalition launched a campaign to urge the US Government to support the Council of Europe Privacy Convention and proposed a resolution for the U.S. Senate recognising among other things that data security breaches along with cases of identity theft pose a substantial risk to American consumers and businesses. They proposed accession to the Council of Europe’s Convention 108 for the Protection of Individuals with regard to Automatic Processing of Personal Data.
The US chose not to do so, but without private sector data protection law, the US remains an outlier in the world. US human rights law focuses on limiting interferences with individual rights by the state (and mainly protects only US persons).
A simplified history of UK data protection law
The process of post-war European reconstruction began by founding the Council of Europe in 1949, swiftly followed by other international and supranational institutions, the European Coal and Steel Community in 1950, Euratom – the European Atomic Energy Community, and the European Economic Community (EEC) in 1957 that went on to become the EU in 1993.
The Council of Europe promotes human rights through international conventions, predominant amongst which is the European Convention on Human Rights of 1950, the “European Bill of Rights”. Always with deference to the European Convention on Human Rights, the Council of Europe has adopted dozens of other major and more specialised human rights treaties such as the Convention on Preventing and Combating Violence against Women and Domestic Violence, and the Convention on Cybercrime to name but two. The Council of Europe group of constitutional experts, known as the Venice Commission, offers legal advice to 47 member states and countries throughout the world. Membership of the Council of Europe (which is open to European states only) is now conditional on being a party to the European Convention on Human Rights and accepting the jurisdiction of the European Court of Human Rights. Noting these are nothing at all to do with the EU. Of all the European states, only Belarus is not a party to the Convention and consequently also not a member of the Council of Europe.
When it came to data protection, the Council of Europe Convention for the Protection of Individuals with regard to Automatic Processing of Personal Data opened for signature in 1981. The Convention contained a set of principles to govern data processing, including that there should be fair and lawful obtaining and processing of personal data, for only specified purposes. In addition, states should not restrict cross-border data flows to other states that had signed the Convention. States could sign up to the Convention where they had national law in place guaranteeing compliance with the agreed standards. It is the first and only binding international legal instrument protecting privacy and data open to any country, including countries which are not members of the Council of Europe.
Accordingly, the UK Parliament passed the Data Protection Act 1984 and ratified the Convention in 1985, partly to ensure the free movement of data and protect trade. The Data Protection Act 1984 contained principles which were taken almost directly from Convention 108.
But in 1995 concern from the European Commission that a number of Member States had not yet introduced national law related to Convention 108 led to worry that barriers may be erected to data flows. In addition, there was a considerable divergence in the data protection laws between Member States. Alongside the importance of the earlier but weaker OECD convention, particularly from a business perspective, it was therefore the European Union Data Protection Directive (95/46/EC) (“the 1995 Directive”) that provided the current consistent basis for the UK’s data protection regime until the GDPR in 2018. The focus of the 1995 Directive was to protect the right to privacy with respect to the processing of personal data and to ensure the free flow of personal data between EU Member States. As a Single Market measure, its primary purpose was to facilitate free movement of data. Ensuring the protection of personal data at a high level was seen as an externality, a necessary price that had to be paid to ensure data’s free movement for trade purposes.
The 1995 Directive was implemented in the UK through the 1998 Data Protection Act which came into force on March 1, 2000 and repealed the Data Protection Act 1984. However, the European Commission found that about one-third of all of the 1995 Directive’s provisions had not been fully or properly transposed in the UK law. The Commission (after a long delay during which this was not resolved) started infringement proceedings over this mis-transposition, but did not pursue this further and the matter ended unresolved with Brexit.
Recognising the risks of emerging technologies and their implications for human rights, and that what had gone before was not enough to meet growing public outcry over data misuses, the 1995 Directive went on to be replaced by the GDPR, published in 2016 and came into application (meaning it directly applied in the EU Member States) from May 25, 2018. The GDPR by contrast with the 1995 Directive, is more explicitly a fundamental rights measure. That may seem like a semantic difference, but is important to understand why the GDPR has a focus on rights, and on people, not data as a product. And in spite of being a regulation that in theory applied directly in the EU Member States, the GDPR contains numerous so-called “further specification” provisions that still leave it up to the Member States to issue further rules on a wide range of matters, within (sometimes broad) parameters laid down by the Regulation.
The UK Data Protection Act 2018 exercised these “further specifications”. The additional provisions fall mainly into three areas; national security, law enforcement, and immigration. In the latter, it deviated from what was allowed under the GDPR in ways that undermined human rights and became the subject of legal action. On May 26, 2021 the court of appeal unanimously found that the UK immigration exemption was incompatible with fundamental rights, including the key principle of the right of access to check that data used about you is accurate.
As this history shows, even “independent, sovereign nations” must be aligned to achieve trade and adequacy, and divergence from shared standards may not be beneficial or sustainable, unnecessarily duplicating administration costs.
What difference does Brexit make?
The UK has since adopted its own version of the EU GDPR which it calls the “UK GDPR”. The UK is now a “third country” with its own data protection rules, although for the time being these quite closely mirror the EU GDPR.
With thanks to Douwe Korff, Ian Brown and with reference to the Cookiebot website, this is a rough summary of the shifting current status.
The EU’s GDPR has been lifted into a new UK-GDPR (United Kingdom General Data Protection Regulation) and took effect on January 31, 2020. The Data Protection Act 2018 has been amended to be read in conjunction with the new UK-GDPR (United Kingdom General Data Protection Regulation) instead of the EU GDPR. It is likely that the UK government will move to consolidate the two amended laws (the UK-GDPR and the Data Protection Act 2018) into one, comprehensive piece of data protection law at a future point. But this consolidation has not yet happened, so to spot the differences between the EU GDPR and UK-GDPR readers need to rely on two so-called “keeling schedules”. These documents show a) the amendments to the EU GDPR that turned that instrument into the UK GDPR and b) the amendments to the UK Data Protection Act 2018, that were incorporated into the consolidated new law. These are both extremely difficult to read and with the various crossings out and different colours in text, may appear to the amateur eye, unfinished.
Regardless of leaving EU membership, the UK is still a member of the Council of Europe and has signed (but not yet ratified) the “Modernised” Council of Europe Data Protection Convention (“Convention 108+”) that was adopted in 2018 to deal with challenges resulting from the use of new and emerging information and communication technologies. Convention 108+ will enter into force upon ratification by all Parties to Treaty ETS 108, or on October 11, 2023 if there are 38 Parties to the Protocol by then.
As we go to print, the British government has outlined the first territories with which it will prioritise striking new ‘data adequacy’ partnerships. Plans are proposed to consult on the future of the country’s data regime. “There is a huge opportunity to build data bridges” claims government Guidance published on August 26, 2021 and the former Secretary of State for Digital, Culture, Media and Sport, Oliver Dowden, said in the Telegraph that “data is oil”.
Our key questions remain unchanged. Will the standards of today’s UK data protection regime be reduced? The proposed changes are not questions of state sovereignty but changes to the rights to govern ourselves as individuals with respect for our fundamental rights and freedoms. How sustainable is policy that alienates young people? Will the government move fast and break things, or build back better for the future of sustainable data access by building what is needed to uphold public trust in the long term?
Data policy must put people back in the picture
We’ve lost the human in conversations about data — we propose re-humanising our language to move forward national debate and actions needed in data policy
The language we use when describing personal data is dehumanising. “The new oil” cannot tell a child’s life story; being framed as “the fuel of artificial intelligence” leaves people feeling used by machines and systems. These metaphors fail to reflect the multi-faceted nature of data or its fallibility, and do not describe the authentic self or engender respect for the person the data is about.
This depersonalisation of the conversation about data results in system and process design that “takes people out of the picture” and does not facilitate or encourage redress or human agency.
“To be “in the picture” is to be present and involved. To “put someone in the picture” is to inform someone what is going on.” Today’s words we use in data policy take people out of the process instead.
We are a decade on from the WEF report, Personal Data: The Emergence of a New Asset Class, which talked about personal data as a commodity and put us in the role of producers, creators and owners. But those are labels that do not work well for data that is produced passively, inferred and observed without our active agreement. People feel disempowered today, not in control of the data that tells others about our behaviours 24/7.
The way some policy makers talk about data in the UK mimics US rhetoric.
Policy makers use transactional language, which sends the message that data is something those in power can exploit for economic gain.
In the US, their data governance is built on the idea that personal data (and people as workforce capital) is a product. In the EU, data governance is founded on a human rights framework, and our data laws protect our privacy putting us in control of data.
There is a fundamental incompatibility between the thinking that is embodied in the language that policy-makers use in US and British data discussions, and the laws that permit the nature of data processing. The UK cannot make drastic changes away from a rights-based model, without risking adequacy with the EU especially given its four-year sunset clause.
The national data strategy as part of a conversation, must not only use words to shape decisions and design actions that are compatible with the law, but the thinking on data must be aligned with the foundations in law. The nature of the UK data strategy and debate must shift to align itself with data governance based on a human rights centric model, or the fundamental mismatch between thinking —as explained in words including data metaphors— and the actions exercised in policy and practice dooms us to failure.
If the government fails to put in place the infrastructure and those foundations to exercise rights, whatever strategy it builds will fail in the same ways they have done to date in big public administrative data projects. care.data failed by assuming it was acceptable to use data in the way that the government wanted, without a social licence, in the name of “innovation”. Or we will see more boycotts like those of the 2021 NHS data grab (aka care.data 2), or schools and families’ refusal to provide school children’s nationality data to the Department for Education 2016-18 when it was discovered that school children’s nationality data would be given to the Home Office for the purposes of the Hostile Environment “once collected”.
Through our research, we have seen children and young people describe data as something that is part of them and their experiences in a community but does not reflect being them— from their behaviours in school to their interactions with law enforcement: data has real-world consequences on their lives. When institutions continually reduce us to data points, the system starts to view us less as humans, and more as products or machine- readable objects. This means we are perceived in ways that are inaccurate, often without our knowledge, and instead the data reader might “fill in the gaps” consciously or not, which takes away any control we have over how we want to be represented.
The persistent exclusion of children from the national conversation only exacerbates this problem. Furthermore, as Boyd wrote in 2014, traditional models of privacy are individualistic, but the realities of privacy reflect the position of individuals in contexts and relationships to others and to institutions.
One possible future is the current one. The data landscape is industrialist and exploitative, where personal data is described as a product, and the framing of the law is about ownership. More and more data is collected and kept and passed around. There are more leaks and losses. The vision is one of turning data from people into products to be fuel for the economy and private corporate “innovation”. Young people are used to harvest and mine as human capital. Rights are not adequately enabled or respected.
That model will fail. Young people do not support it and even take action to resist and refuse such collections by the state and companies. Data quality for public interest research is harmed. There is significant reputational risk for organisations. It is not sustainable.
The second is the future that young people (and we at defenddigitalme) want policy makers to encourage — where data is not about using people-as-products but data about them is used with their involvement and in ways that understand their humanity is part of the data about them. They want to have agency and control over who they choose to share what information with, and why; with respect for confidentiality, and handled with dignity. The framing of their expectations in law is a human rights based model and needs infrastructure to exercise their role in it. And you do not have to trade away your privacy if you are poor. There is fairness, not ownership.
We propose new, better ways of talking about data: what if data was more like a mirror that shows others a part of yourself? All too often today, the data relationship between individuals and institutions is a one-way mirror with enormous power imbalance. Or perhaps data should be talked about as a lens through which to view the world? What if we started thinking about data in the same way we think about art?
Not celebrated for its utility, but rather an expression of the world that helps us see and comprehend complexity. The surrealists expressly used metaphor to explore interpretations of life, death and time. Their art was a way of interpreting reality or imagining alternative realities. Understanding that personal data can only tell part of a reality, or reflect only a fragment of a person’s life story and that interpretation can depend on the perception of the beholder is vital when data is used in decisions and policy solutions to problems are framed by metaphors that can shape the solutions.
State systems becoming ever more “data driven” is driving out the human in the data. “The data” cannot contain the complexity and fullness of human life, we are “more than a score”. Today’s systems often fail to handle that and their decision-making is built on data that is incomplete and inaccurate and looks backwards at what was and the behaviour of people who went before us. Systems look for patterns in the past and authorities are encouraged to predictions based on it, reinforcing historic biases and discrimination. Systems have no compassion and no leeway on the reason for missing a DWP appointment and can only issue a sanction that is hard to appeal. Technology circles debate the ethics of Artificial Intelligence, all the while trying to retrofit ethics onto unethical systems executing unethical policy.
Complex discussion requires clarity and logical expression. There is not only a practical need but a moral obligation on policy makers, to be able to handle the demands of this discourse and to put the human back into conversations about data about us.
We must reconcile the focus of the UK national data strategy, with a rights-based governance framework to move forward the conversation in ways that work for the economy and research, and with the human flourishing of our future generations at its heart.
Bibliography
Baiili. England and Wales Court of Appeal (Civil Division) Decisions: The Open Rights Group & Anor, R (On the Application Of) v The Secretary of State for the Home Department & Anor [2021] EWCA Civ 800 (26 May 2021). https://www.bailii.org/ew/cases/EWCA/Civ/2021/800.html
Barassi, V. (2020) Child Data Citizen: How Tech Companies Are Profiling Us from Before Birth MIT Press
Coleman, S., Pothong, K., Vallejos Perez, E., and Koene, A. (2017) The Internet on our own Terms: how children and young people deliberated about their digital rights. Supported by 5Rights, ESRC, Horizon, University of Leeds and University of Nottingham.
De La Chapelle, B. and L. Porciuncula (2021) We Need to Talk About Data: Framing the Debate Around Free Flow of Data and Data Sovereignty. Internet and Jurisdiction Policy Network https://www.internetjurisdiction.net/news/aboutdata-report
Dowty, T. (2008) Overlooking children: An experiment with consequences. Identity in the Information Society, 1(1), 109–121. https://doi.org/10.1007/s12394-009-0010-x
Ferreira, J. (2012) The world in thirty years is going to be unrecognizably datamined and it’s going to be really fun to watch. Former CEO of the adaptive learning company Knewton, at the White House US Datapalooza in 2012. https://youtu.be/Lr7Z7ysDluQ
Flusberg, S. J., Matlock, T., & Thibodeau, P. H. (2017) Metaphors for the War (or Race) against Climate Change. Environmental Communication, 11(6), 769–783 https://doi.org/10.1080/17524032.2017.1289111
Hof, S. van der, Lievens, E., Milkaite, I., Verdoodt, V., Hannema, T., & Liefaard, T. (2020) The Child’s Right to Protection against Economic Exploitation in the Digital World. The International Journal of Children’s Rights, 28(4), 833– 859. https://doi.org/10.1163/15718182-28040003
Hauser, D. J., & Schwarz, N. (2015) The war on prevention: Bellicose cancer metaphors hurt (some) prevention intentions. Personality & Social Psychology Bulletin, 41(1), 66–77. https://doi.org/10.1177/0146167214557006
Lakoff and Johnson (1980, 2003)The University of Chicago Press, Metaphors We Live By ISBN: 0226468011
Lancaster, S. (2018) You are not human: How words Kill ISBN: 9781785904073 Biteback Publishing
Marwick, A. and Boyd, D. (2014) Networked privacy: How teenagers negotiate context in social media. New Media & Society, 16(7), 1051–1067. https://doi.org/10.1177/1461444814543995
McNeil, J. (2020) Lurking: how a person became a user. MCD Books / Picador. ISBN: 9780374194338
Puschmann, C. and Burgess, J. (2014) Big Data, Big Questions | Metaphors of Big Data. International Journal of Communication, [S.l.], v. 8. ISSN 1932-8036. Available at: https://ijoc.org/index.php/ijoc/article/view/2169
Reiman J. (1976) Privacy, intimacy, and personhood. Philos Public Aff 6(1):26–44 Reiman, J. H., & Reiman, P. J. (1997). Critical Moral Liberalism: Theory and Practice. Rowman & Littlefield
Selwyn, N. (2021) The human labour of school data: Exploring the production of digital data in schools. Oxford Review of Education, 47(3), 353–368. https://doi.org/10.1080/03054985.2020.1835628
Research on conceptual data metaphors
Julia Slupska
Copy
Georgia Iacovou, Jen Persson
Designer
Sam Ballard
Illustrator
Gracie Dahl
Thanks
We are indebted to the youth participants and The Warren Youth Project who supported us, helped shape our thinking, and gave their time to discuss the ideas in a workshop in April 2021.
We thank our funders the Joseph Rowntree Charitable Trust and the Joseph Rowntree Reform Trust. We also appreciate the contribution of many others. In particular we want to thank Ade Adewumni, Douwe Korff, Ian Brown, Jeni Tennison, JJ Tatten, Lee Andrews, and Lydia Rangeley.




 The way you understand a problem has a big impact on how you construct a solution.”
The way you understand a problem has a big impact on how you construct a solution.”