Pupil data: Respecting rights for edTech and the National Pupil Database
Blog / April 29, 2026
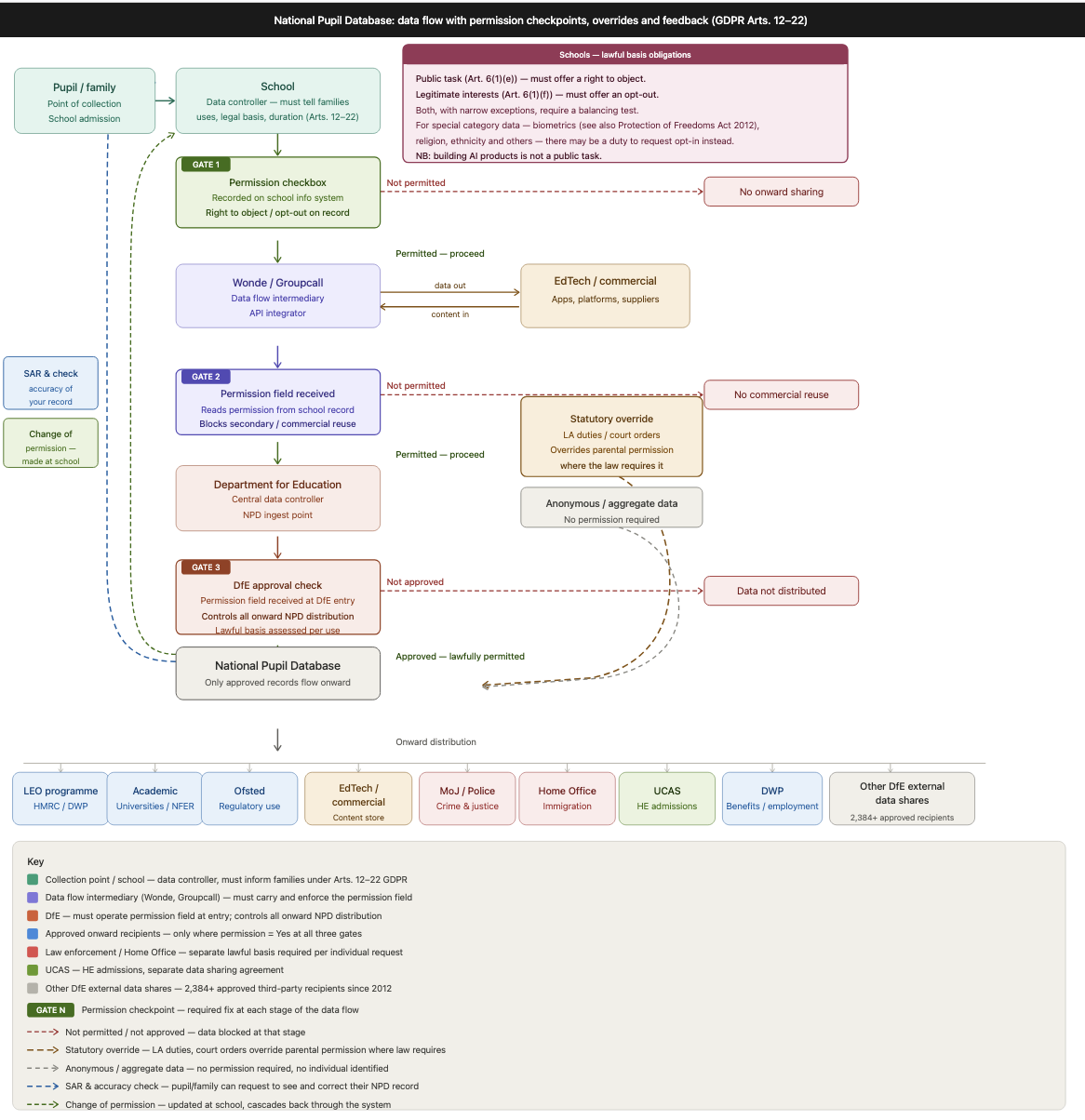
In our review of DfE pupil-level data distribution since 2012, when the Department for Education began handing out identifying, individual level pupil data in “approved data shares to external, third-party organisations” at national level and in bulk (each distribution of thousands and millions of pupils’ records each time), we proposed what the data model might look like for the parental controls and the flags needed by the data intermediaries and school information management systems providers to action their choices.
{kind=link}
Here’s what the front end might look like for parents and pupils in the app they already have from their MIS provider, like MyChildAtSchool, or the intermediary like Groupcall or Wonde. This is where they can make those choices known.
Findings from a 2024 collaboration between DSIT and DfE to deliver a programme of deliberative research exploring parent and pupil attitudes about the use of AI in education, included that, “Both parents and pupils strongly felt if data is pseudonymised, identifiers should be held at a school level and ought not to be shared with tech companies or the government.” (5.3). Data processing by the state requires a social licence that today does not exist even for less identifying data than is currently given away. If the DfE wants to expand data distribution and reuses further, this is how to create the tool to build trust and respect both the law and what parents and pupils want.
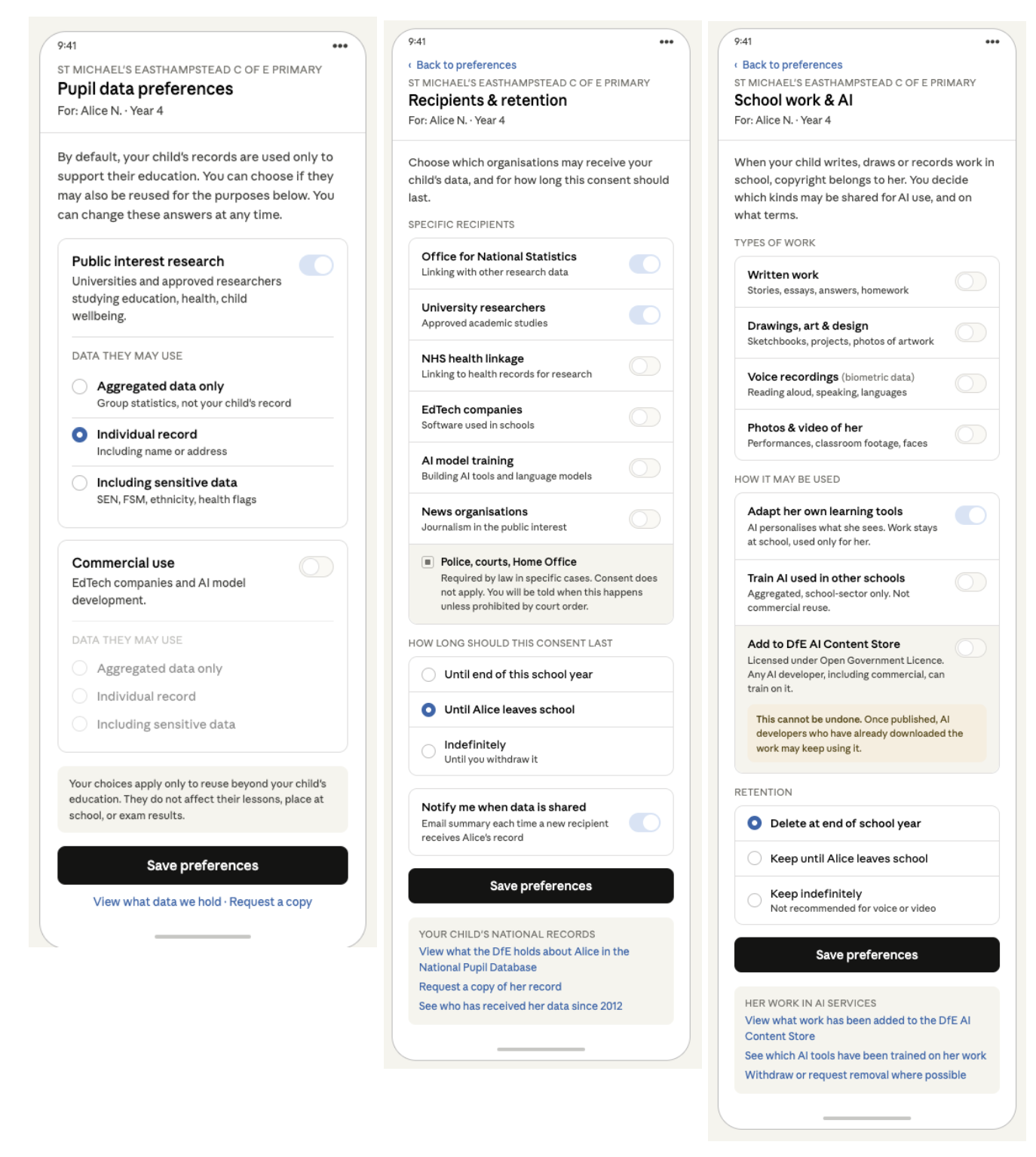
Screen 1: the screen shown here illustrates a parent who has chosen to permit research access at individual-level, and no commercial reuses.
Default = no distribution for indirect and commercial reuses. Both toggles start off. This matches that current law requires consent / opt-in for sensitive data, plus a balancing test or Right to Object exists for everything else, and there is no such thing as “assumed consent”. This is what MPs are arguing for in social media default protections, why should commercial reuse of children’s data from going to school, be less safe?
Two independent purposes, three data scopes each. A parent who’s fine with academic researchers using group level (aggregated) records may still want commercial AI training blocked entirely — the matrix lets them say so without forcing one answer to govern both.
“Sensitive data” is its own step up, not a hidden default. SEN, free-school-meals status, ethnicity and health flags aren’t quietly bundled into “individual record” — the parent can actively choose the third option. This reflects what parents say they want, from the DfE research (5.3) to our own at Defend Digital Me (2018) and public attitudes work by UCAS and elsewhere from the last decade.
Footer reassurance. The line about choices not affecting the child’s place at school or exam results matters: without it, parents may reasonably worry that opting out is punitive. The relationship is between a school and a family, so the framing is school-branded, not DfE-branded.
Screen 2: A second screen can offer granularity, rather than crowding this one. Some of these processes do not yet exist, but should by law.
What consent can’t cover. Police, courts and Home Office sit in a separate locked block at the bottom of the recipient list. Parents and pupils should know that this data distribution happens and that ticking boxes won’t close it. Pretending otherwise — any hidden uses –would harm public trust.
Default retention is bounded. “Until my child leaves school” is pre-selected rather than “indefinitely”. The Unique Pupil Number is supposed to lapse at 16 but doesn’t yet (DfE Guidance 2.1) — this format mirrors the policy that’s meant to exist but currently does not. Alternatives could be around pseudonymisation.
Notification on by default. If a new recipient gets the record, the pupil and/or parent should be told. This is what makes the audit trail mentioned in the article actually visible to families rather than locked behind a Subject Access Request that they do not know is even possible.
The footer has three explicit links. The links to see the record, and “request a copy” meet rights of subject access that already exist under data protection law. This is what 79% parents said they wanted to be able to do, when polled in 2018. However, “see who’s had it”– knowing who has received the pupil data via the DfE since 2012 may not be possible yet if nothing has changed since we last asked, but a data subject, the child or their parent, should be able to know which distributions touched their child’s record and should be made possible going forwards.
Screen 3: And what about the expanding data uses for AI products via the edTech used in a school but that are reusing the pupil data and content they receive today? Or new uses via the Department for Education, such as using consented work in the DfE Content Store? You could use the same mechanism and the interface and relationship is still at the point where the human relationship exists between family, child and education — the school, avoiding any necessity for the DfE to manage thousands of relationships.
Name copyright first. “Copyright belongs to her.” Children own the IP in their school work, even at primary school age. The DfE rightly recognises this already. This isn’t a privacy choice, it’s a licensing decision.
Three tiers of use, with the OGL warning attached only to the riskiest. The Content Store releases content under Open Government Licence v3.0, which means once it’s in there, any AI developer including commercial ones can train on it, indefinitely, with no obligation to take it down if you change your mind. That’s qualitatively different from the other two options, so it gets a callout. The other two don’t, because they shouldn’t carry the same friction.
Default retention is shorter. Screen 2 defaulted to “until leaves school”. Here the default is “delete at end of school year” — because creative work is more identifying (handwriting, voice, face) and the educational purpose decays faster. A Year 4 essay has no educational reason to follow her into Year 11; however the reuse might be forever once used for developing AI products. The difference is noted on screen 3.
“Not recommended for voice or video” sits next to the indefinite option as a soft warning. Voice and face data are biometric data and they don’t anonymise the way a test score does. It should be defaulted to off, if considered for re-use by third parties at all.
The footer is AI centric. Screen 2’s footer was about pupil records since 2012. This one is about AI products that have been trained on her work, and it needs a different audit trail because the harm here is downstream model behaviour, not just data possession.