National pupil data distribution: a review in 2026, and how to fix it
news / April 15, 2026
In ten years of efforts to improve Department for Education handling of national identifying pupil data distribution, and challenge misuse, we regularly take 2 steps forward and 1 step back. Now the DfE plans a giant leap into more data collection, outlined in the Schools White paper, to develop its Data Spine. Is that to be this NHS-data-linked spine? The note on page 109 saying, “It must be noted that LA systems may not be as secure as NHS systems,” merits far more attention.
The new placeholder for a single unique Digital ID in the Children’s Wellbeing and Schools Bill* is likely to be the NHS number according to debate in May 2025. It’s all still fairly cloak-and-dagger with no clear explanations given to Parliament in the Children’s Wellbeing and Schools Bill scrutiny of the planned scope, or any safeguards. The idea that this should become just another consistent child identifier passed around Local Authorities and their ancillary third parties, deserved far more scrutiny, (see above). A year ago, in January 2025 the Department for Education Science Advisory Council was tasked to produce a paper highlighting use cases for a Single Unique Identifier. Has anyone seen what they proposed?
For the rights-management model the DfE needs to be able to manage the answers to some of the data implications from these questions, go straight to our proposed model and Can we Fix It? at the end of this post.
{kind=link}
A review of a DfE pupil-level data distribution since 2012
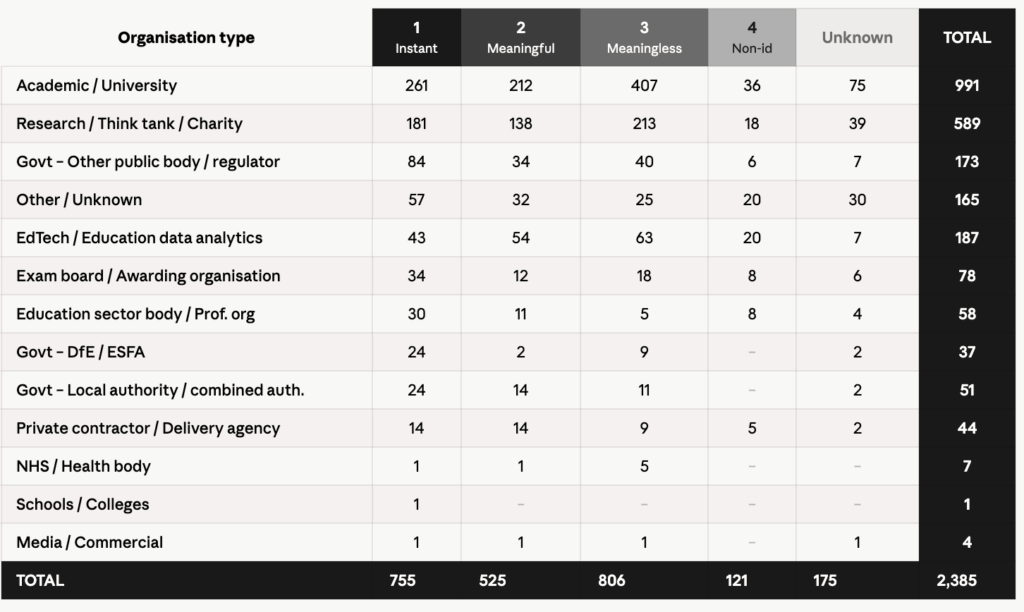
Since 2012, the Department began handing out identifying, individual level national pupil data in “approved data shares to external, third-party organisations”. The distributions to date have been recorded in 27 different split and archived files, none of which are very easy to access any more via the DfE webpage and national archives. So we have now created a merged and cleaned review of them, up to the end of 2025, and identified (and remember, each release is a batch in bulk, not data about just one person):
- 1,112 unique DSAP-approved entries,
- 1,273 legacy NPD requests, and
- 80 unique pre-2018 standing shares.
A total of at least 2,385 unique and separate distributions [from a cleaned set of matched 2,465 records]. Each distribution may contain thousands or millions of individual longitudinal records. The database holds over 28 million people’s data now, and when last asked, the Department did not track how many individuals’ data was in each release. Most of the data are both identifying, and sensitive. Of 1,273 NPD legacy requests, tier 1 (identifying/highly sensitive) is the largest at 494 (39%), followed closely by tier 2 at 473 (37%). We have erred on the conservative undercount side, given the challenges of the matching process.** The volume of data distributed as releases grow, year on year as expected in 2017 when we last did this exercise.
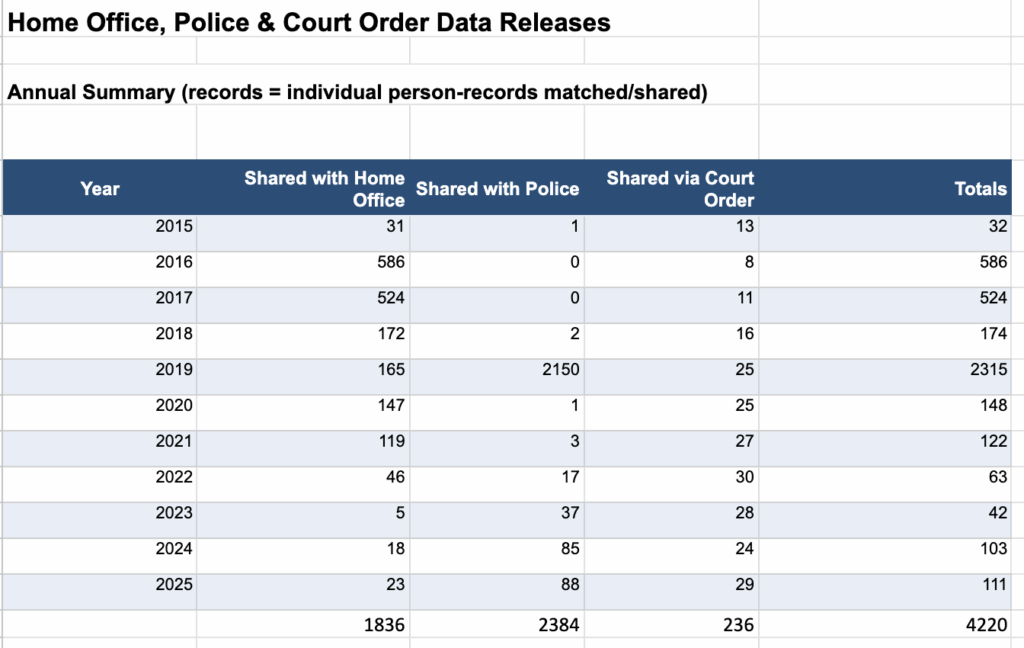
In addition, annual and monthly tables for Home Office show 1,836 records about individuals shared after 7,321 requests for matching, plus Police (2,384 records), and Court Orders (236 requests) — all between July 2015 to December 2025. The transparency over counting them has at least improved, since 2017, even if accountability for what happens as a result, has not.
Is it research or is it operational? This has implications for the lawful processing of data and rights management
Only transparency over these practices will empower people and help us all better trust in the decisions taken by public bodies. But many uses remain extremely opaque and unaccountable. In 2019, Merseyside police got given all 2,136 pupils’ records who attended just one school in a four-year period, out of the National Pupil Database (“NPD”), confirmed via FOI in September 2022. To date they refuse to release why this was necessary at national level, instead of asking the school. That accounts for 97% of the entire 10-year police total. Even the Cabinet Office had requested a full copy of NPD data in 2012. Commercial reuses have included to create heat maps for estate agents of pupil home addresses, and identifying releases to national newspapers. We’ve been reliably informed by a journalist that “entire copies of the database” have been seen loose in the wild, which is unsurprising if copies of data may be onwardly shared.
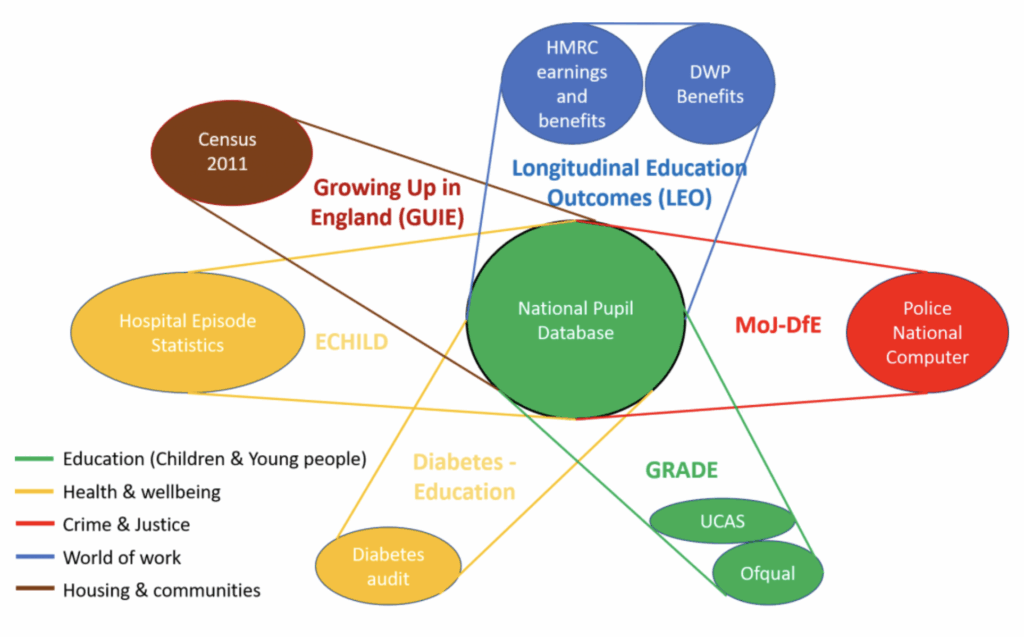
Cross linkage from the DfE is creeping into every arm of the state already.
The National Pupil Database, built from children’s school records, is now at the heart of cross departmental linkage between Census records, DWP, HMRC, Health, Home Office, and National Police Computer and Justice records for millions of adults, as the school children’s data ages and is retained forever. A spine that already today has arms that reach into so many parts of private and family life; mixing the public interest research purposes with increasingly operational and punitive reuses. We wonder if participants in the National Data Library focus groups were informed of this a year ago, given the claim made about the,”assumption that the government already collects and shares vast amounts of data, despite the reality being more limited.” Public attitudes remain very similar to ADRN findings in 2014 on deidentified data, and consistent with parents views on edTech we have surveyed, DotEveryone and near all the other similar attitudes findings, in the decade since. Like 9 out of 10 of the 37,000 UCAS students asked in 2015, people expect to be asked for consent. Findings from a 2024 collaboration between DSIT and DfE to deliver a programme of deliberative research exploring parent and pupil attitudes to the use of AI in education, included that, “Both parents and pupils strongly felt if data is pseudonymised, identifiers should be held at a school level and ought not to be shared with tech companies or the government” (5.3). Data processing by the state requires a social licence.
DfE still has 2019 guidance on Unique Pupil Numbers, saying, “the UPN must lapse when pupils leave state funded schooling, at the age of sixteen or older,” but the DfE does not anonymise or remove the UPNs in its own controlled datasets. The UPN is a linkage key, and supports far more than what the then Labour Minister promised was only statistical purposes, when names were first introduced to the database. “The Department has no interest in the identity of individual pupils as such, and will be using the database solely for statistical purposes, with only technical staff directly engaged in the data collation process having access to pupil names, ” said Stephen Timms in 2002. Your unique pupil number stays with you forever. Your NHS number stays with you forever. If identifiable records stay attached to the number, so does everything possible to infer from longitudinal records, the attached risk and potential harms from loss, theft, or misuse.
As punitive reuses of national records increase, so public trust further diminishes in admin data, both its reuse and handing it over in the first place. National projects like introducing a national digital ID as a spine for the database state, along which they plan to “mainline AI into the veins“of our interactions with public services, are viewed as high risk for future harms and its intrinsic power imbalance. This has implications for future policy success. How do we solve it?
Solving the challenge
The lawful obligations the state must respect in data protection law to uphold our human rights, take us back to first principles. Indefinite identifying data retention is not generally permissible, because the reason personal data is collected tends to wear off over time for administrative purposes. A child grows up. You get out of jail. You get well, or not. Data Protection law grants research purposes an exemption on the basis that research is compatible with the original reason it was collected for. This used to be s33 of the Data Protection Act. The purposes were to permit bona fide public interest research, while putting safeguards in place that the person could not be identified nor harmed as a result.
The problem with the National Pupil Database and other emerging reuses of public admin data in Westminster, is that without parliamentary debate or change of law or oversight, departments have taken it upon themselves to start new policy which carries out data linkage and distribution. Those breach purpose limitation and stray from research, into operational reuses. That nullifies the research exemption that permits the indefinite retention of [the same] identifying records. Suddenly your entire research database is at risk of being required to be made anonymous after time-limited use, or even having the identifying data destroyed, and you must give the people in it ways to exercise their right of subject access, and all their other data rights, including being informed. Until around 2017 the DfE refused to accept it was bound by a duty to meet a subject access request. When its operational reuse for immigration enforcement including to “create a hostile environment,” was exposed in 2016, that fell away. DfE since introduced a bit of a SAR process that nearly no one knows about and doesn’t work well at national level, or for children, and no one has told pupils past or present it exists.
Either you can have a restricted-to research purposes database and enjoy its research exemptions, or it can be operational and must support subjects’ full rights. The Departments cannot lawfully both have their cake, and eat it. The Department for Education must decide. Is the National Pupil Database a research database or is it operational?
Fig.1 source ADRUK
What about the DfE ICO audit?
The ICO wrote to us on connected issues as part of their work into our detailed regulatory complaint case in 2019 and other prior joint-complaints against the DfE on nationality pupil data processing. They found wide-ranging and serious data protection issues prior to the audit about national pupil handling. It backed our Defend Digital Me findings from our 2018 parents’ survey, that parents and pupils don’t know national pupil databases exist. “This investigation has demonstrated that many parents and pupils are either entirely unaware of the school census and the inclusion of that information in the NPD, or are not aware of the nuances within the data collection, such as which data is compulsory and which is optional. This has raised concerns about the adequacy of DfE’s privacy notices and their accountability for the provision of such information to individuals regarding the processing of personal data for which they are ultimately data controllers. “regarding compliance with articles 12, 13 and 14 of the GDPR. Our view therefore is that the DfE is failing to comply fully with the GDPR in respect of these articles.“
We are once again asking for the full ICO 2020 DfE audit report to be published, not least to show all of us who may be in it and who pay for its maintenance, what is known about these breaches of law (a) at the DfE and (b) at the Regulator, and (c) what remedial actions to fix them the DfE has been told to action, if any, in what timeframe.
We want to know from our case, what the Regulator’s audit did and did not cover. The basic rights of data protection law are intended to enable use of information whilst upholding the human right to privacy and confidentiality, and to protect us from misuse and harms we don’t even know about. One of those was exposed in the press during the audit, and though important, it was the only real part of the follow up the ICO acted on. The Trustopia Learner Records’ Service (“LRS”) case study shows how handing out data, rather than permitting access to trusted researchers is unsafe. But 3 years later, the conclusion was only that the DfE got told off, the company ceased trading, and the directors were never held accountable. The Department’s legal advice at the time was not to pursue breach of contract pending the ICO investigation, but by the time it concluded, legal action was no longer available. Nothing visibly changed for the public to enable their rights management in either the LRS or the NPD.
Change must now happen. Everyone has had their rights denied since the database was built, and the system mechanisms have not existed to make them possible. Pupils past and present don’t know they can access a copy, have it corrected, or how. Those breaches of rights continue, including those first identified in 2019 in writing to us by the ICO itself, failures of fair processing, purpose limitation, accuracy, retention, integrity and accountability for onward reuses by the data recipients. Harms to rights are growing through scope creep much of which is opaque and we must consistently fight to expose.
Six years after the ICO DfE audit took place, when will the Department or ICO address the remaining open questions? If they refuse to release what the audit covered, we may never know. But this is an inadequate foundation to keep building on. Plans for the Data Spine in the White Paper will collapse if these things are not fixed. Maybe not today, maybe not tomorrow, but soon, and for the rest of their life, this database is how the State looks at our kids. But families are starting to push back which will only grow and will clearly become an election issue. “Will you continue to commercially exploit our children or commit to an opt out, dear Candidate?”
- There is still no fair processing (telling the people whose data it is, what it is used for or where it goes for how long or why (“as required under Articles 12,13 and 14 of the GDPR”);
- It is still not clear to schools as data controllers, what their role is in telling families what is collected under what law and what is optional, one of the key failings required by law highlighted in the summary of the audit that was published in October 2020;
- There is no apparent change in the “over reliance on public task” lack of identified supportive legislation, or the “limited understanding of the requirements of legitimate interest” necessary “to ensure the use of this lawful basis is appropriate and considers the requirements set out in Article 6(1)(f) of the GDPR” found (page 6/6);
- There is no right to object, balancing test and no opt out offered on the collection of, let alone the reuses of, any sensitive and identifying pupil data from the NPD, at local or national levels distributed to third-parties;
- There is still no user-friendly Subject Access Request process, and not one suitable for children at all, or that 28 million people know about;
- And no way to know whether your own data have gone or are still with any of the over 2,384 releases of identifying and sensitive data to third parties since 2012.
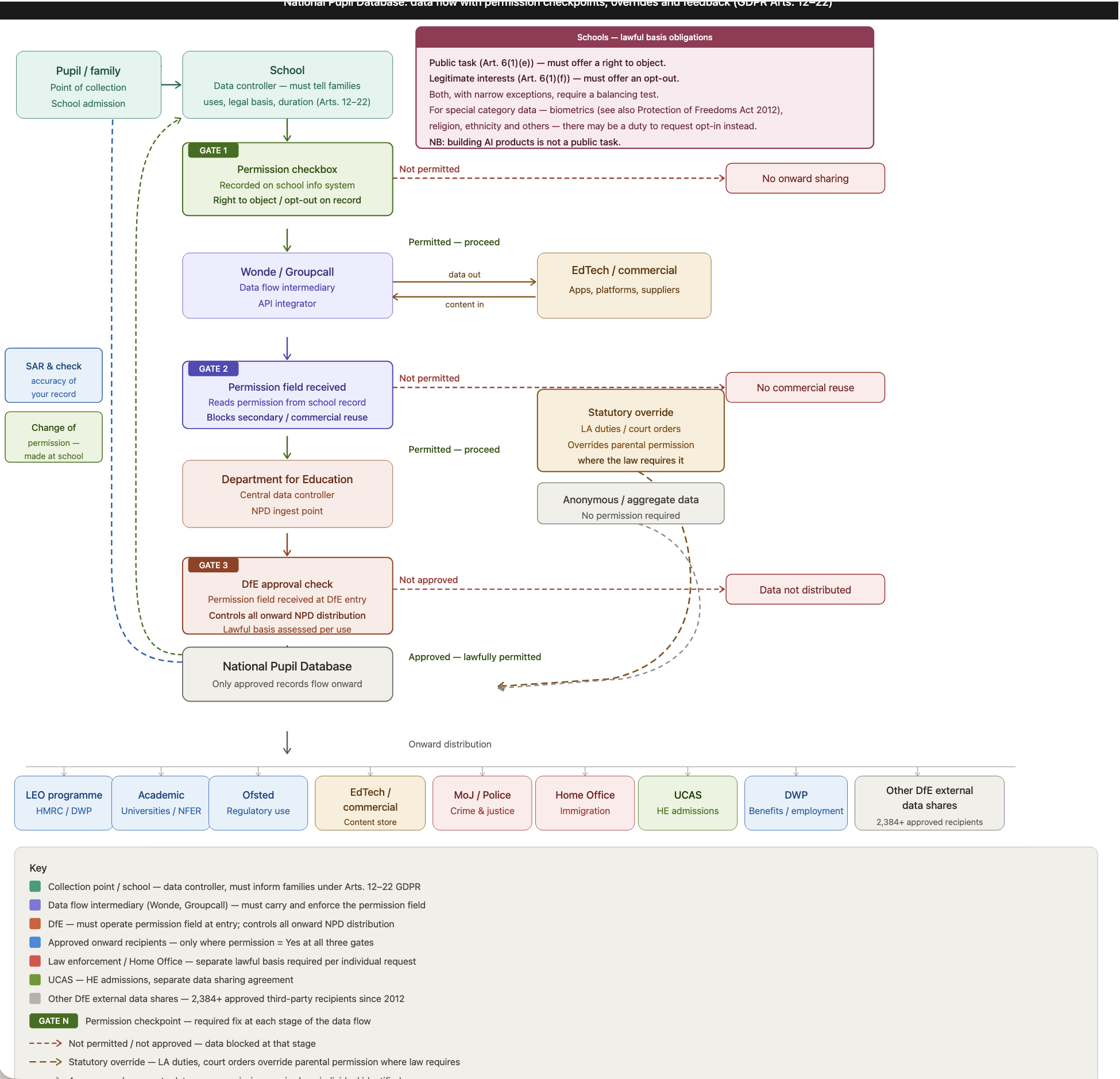
Can we fix it?
Yes we can. Fortunately the answers are reasonably straightforward. Let us assume the government chooses to continue today’s reuse as-is model, or to expand it. People need told the databases exist and how to exercise their rights already established in law. We need a couple of technical and interoperable signals built into schools information management systems, in similar ways that those SIMS regularly get extended with new fields or codes to collect more data, for example to collect school preferences. The same just needs built for passing on re-use preferences.
The question and answers the DfE and the school settings need — whether or not pupils (and parents while pupils cannot) want to exercise their rights to object (under public task) and right to opt out (under legitimate interest) with respective balancing test assessments — can be made combined at one point of contact, in the school admissions process. Adding a check box to those data collection forms, also gets coded into the SIMS, and a receiving field on the integrators (Wonde, Groupcall et al) or indeed on any edTech that are not using an API integrator. Similarly the receiving field needs to exist at the DfE point of entry for the data flow between the educational setting and the onwards integration and distribution to other multiple systems at the DfE including the National Pupil Database. Any onward distribution is therefore fully auditable and lawfully permitted, it is or is not shared according to the law and what pupils (parents) have indicated on their record at the point of collection. Any changes or refreshers of that, or questions that need to be asked from top-down, are similarly to make where the person has the relationship with the system, namely, the school setting. The DfE need not be involved in parent communications. The relationship exists between families and schools. For the purposes of creation of AI or commercial reuses, and similar Content Store IP approvals, (or indeed, the National Data Library) we just need to build it. And the system must prioritise the protection of educational purposes and the child’s right to education.
“It’s better to do one job well, than two jobs… not so well.”
Fig.2 A map to identify where fixes can be applied to solve the missing rights’ management requirements. (v1.0 and will evolve over time). This maps the as-is and shows some of the current data flows without comment on whether they ‘should’ be or not. There are also safer ways to access data and make it open safely for research access, than to distribute it. The rights, rules and permissions for reuse, apply in any case. If the DfE wants more data reuse for the Content Store and Data Spine Distribution or even national ID, then they must fix the as-is, or remodel it to respect rights. Yes, the conversation needs to be had, what are direct and indirect data uses and what can people have a say in or control or not. But rights cannot be ignored.
Other versions are possible. This builds on our recommendations from mapping the data flows in state education, in, across and out of state education in 2020. We welcome comment.
Defend Digital Me, April 2026

On the matching, cleaning, and counting methodology
**Although we have done our best to be accurate, and computer aided, we can only work with the available data and the legacy coding and tables vary across different years. 173 records 2012-2016 were uncoded. NPD requests only have a single tier code, not separate identifiability and sensitivity scores like DSAP entries do. So the NPD tiers were mapped as follows: Tier 1 identifiability 1 plus sensitivity B, Tier 2 identifiability 2 plus sensitivity C, Tier 3 identifiability 3 plus sensitivity D, and Tier 4 identifiability 4 plus sensitivity E. This is a reasonable approximation given the DfE’s own tier descriptions, but comes with a series of caveats in context and missing some 2023 data as we were unable to access two files from 2023.
- There are 83 orgs in both DSAP and NPD — not duplicates but the same organisations, from two different eras of data sharing (pre-2018 NPD licence + post-2018 DSAP approval). Separate legal instruments, separate data flows.
- 57 DSAP rows have near-identical purpose text — but these are not duplicates. Each has its own DS reference number. DfE issues separate references for each extract within a project (e.g. four cohort pulls for the same UCL/BIT study get DS00290, 291, 292, 293).
- 2 umbrella SLA entries (ONS and DfE/UKDS) are counted once each. Their sub-releases are listed separately under their own DS numbers.
- 773 NPD rows have no DR number these are all from the Apr 2012–Jun 2016 file which predates the DR numbering system. These are unverifiable by reference cross-check.
Full datasets and workings can be downloaded here.
Tables show the number of releases grouped through our own coding in Fig.1 . A total of 2,385 unique and separate distributions [at minimum from a cleaned set of matched 2,465 records]. Each distribution may contain thousands or millions of individual longitudinal records.
Fig. 1 Each release is in bulk (1 may = millions of individuals’ records) and the coded grouping are only for interest to estimate where the weight of self-described purposes are concentrated, noting that there is some overlap e.g. Commercial and data analytics companies; whereas in Fig. 2 Home Office, Police and Court Order releases are at individual level (1 = 1 person)
*Edited April 16, to remove extra section on the HomeEd implications for the Children’s Wellbeing and Schools Bill, to simplify, and to clarify.